"
회사에서 타 부서와 친목 도모 겸 워크샵을 했었는대 당시 발표했던 자료들을 기록한다.
인공지능과 친숙하지 않은 사람에게 설명하기 위한 자료로 기초적인 개념위주이며 표현을 최대한 쉽게 하도록 하였다.
"
# 인공지능

인공지능
인공지능, AI(Artificial Intelligent), 인공으로 만든 지능
실제 생물과 다른 기계, 프로그래밍의 지능을 말하며 폭 넓게 확률론적 계산영역 부터 룰 베이스 프로그래밍 까지 “인공지능”이라고 불릴 수 있다.
기계학습
보통은 확률론적 계산의 반복과 갱신으로 이루어지며 대표적으로 단순 회귀선 추정 같은 모델부터 다차원 벡터 추정 모델등 수학적인 증명에 의해 결정할 수 있는 모델과 뉴럴 네트워크 기반의 블랙박스 유형의 모델을 모두 포함한다.
뉴럴네트워크
기계학습과 딥러닝 단계에 중간에 위치한 가장 기초적인 신경망 기반 모델링으로 사람의 뇌를 형상화 한 모델이다.
이 모델링을 기초로 오늘날 대세로 자리잡은 딥러닝 모델링으로 발전하였다.
즉 인공지능 이라고 하면 오늘날의 대중적인 AI 모델인 알파고나 GPT같은 강인공지능을 넘보는 생성형 AI뿐만 아니라 단순 회귀선 추정, 계산, 지식 벡터화 등 여러 개념을 통틀어 AI라고 한다.
아래서 부터, 뉴럴네트워크를 기반으로 하는 인공지능에 대해 주로 설명한다.
벡터

수학적 개념에선 단일 숫자로 표현 할 수 없는 공간이나 수량, 집합 등의 크기와 방향을 표현하는 값의 형태이다.
벡터의 크기는 벡터 공간의 총량을 의미하며 1-norm(|X|) 또는 2-norm(||X||)로 표현하며 음수는 불가능 하다.

벡터의 방향은 벡터의 성분의 순서로 관측되는 각도(기울기) 또는 좌표공간을 의미한다.

벡터는 n-차원일 수 있으며 개발 편의상(Numpy 패키지 또는 대 다수 인공지능 관련 패키지를 사용할때) 배열, 행렬, 텐서 등으로 표현 하기도 한다.

선형대수학에서 행렬곱은 특히 현대 뉴럴네트워크 기반 인공지능의 핵심 연산이다.
여기서 크기 [n, f] 행렬, X는 n개 를 f개의 피쳐로 표현한다 라고도 이해 할 수 있다.
| 다리 개수 | 크기 | 식성 | 알 | |
| 코끼리 | 4 | 큼 | 잡식 | 없음 |
| 물고기 | 0 | 보통 | 잡식 | 있음 |
| 토끼 | 4 | 작음 | 초식 | 없음 |
예컨대 위와 같은 각 동물의 특징을 표현한 표가 있다고 생각하면, 각 코끼리, 물고기, 토끼라는 3개의 동물을 다리 개수, 크기, 식성, 알 등의 4개의 특징으로 표현한다고 볼 수 있다.
Perceptron
뉴럴네트워크에서 핵심 개념으로 "Nerual" 이라는 이름처럼 인간의 뇌의 시냅스를 형상화한 모델이다.

뉴런의 연결을 가중치(W), 편향(b)으로 표현 할 때 배열곱으로 표현하면,

여기서 W와 b를 θ 로 한번에 표현하기도 한다. 즉 하나의 퍼셉트론은 (일반적으로) 가중치, 바이어스를 포함하여 입력과 가중치에 대해 행렬곱을 하고 편향을 더해주는 일종의 장치(또는 함수)로 이해 할 수 있다.
Multi-Layer Perceptron
각 단일 Perceptron을 하나의 layer라고 표현하면, 멀티 레이어 퍼셉트론은 이름 처럼 다수의 layer로 이루어진 모델이다. 즉 MLP는 다음과 같이 표현 할 수 있다.

가중치에 대한 이해
위의 표로 돌아와서,

표의 데이터를 [3, 4] 의크기를 갖는 배열로 표현해보자.
그리고 가중치라는 명칭은 아마도 어떤 무엇인가에 대해 가중함으로써 어떤 값이 중요하고 덜 중요한지에 대한 값이라고 표현해보자.
위에 동물을 표현한 특징 중, 가장 중요한 특징이 무엇일까? 일반적으로 볼 때 우리는 당연히 "크기"로 생각 할 수 있다.
만약 이 4개의 특징을 압축하여 하나의 특징으로 표현한다고 하면, "크기" 에 계산되는 위치의 가중치를 높이면 아주 좋을 것이다.
가중치의 크기가 [4, 1] 인 배열일 때, [3, 4]인 배열에 배열곱을 취하면 [3, 4]*[4, 1] => [3, 1] 크기의 배열로 조정이 되는대, 이는 3개의 동물을 하나의 특징으로 표현한 배열이라고 할 수 있다.

그럼, 여기서 이 특징들을 내재된 숨겨진 특징으로 확장해본다면?
[4, 5] 의 크기의 가중치라면 위와 같은 논리로, 개의 동물을 5개의 특징으로 표현하는 배열이라고 해석 할 수 있다.

즉 기존 4개의 특징이 f개의 특징으로 확장 또는 축소하여 데이터를 표현하는대, 이는 곧 특성을 다양하게 해석하고 변경한다라고 말 할 수 있다.
출력에 대한 이해
가중치로 데이터의 표현을 확장하거나 축소하였다. 여기서 간단한 MLP 모델의 구조를 보자.

각 레이어는 3개의 데이터를 5, 10, 3 개 등의 특징으로 표현하였다. 이 모델을 3개의 데이터를 4개의 특징으로 코끼리, 물고기, 토끼중 무엇에 가까운지 분류하는 모델이라고 한다고 하자.
마지막 [3,3] 출력 행렬을 y_hat 이라고 하고 우리가 원하는 정답을 y라고 할 때, y_hat 행렬을 y와 가깝도록 계산되도록 각 레이어의 가중치와 편향 값이 정해지면 될것이다.


즉, y_hat 값을 정답인 y와 가깝게 되도록 가중치와 편향 값을 각 레이어에서 조정하는 행위가 바로 지도 학습이라고 할 수 있다.
가중치 업데이트
마지막 출력값과 실제 정답값이 비슷하게 (가깝게) 되도록 가중치를 업데이트 한다.
여기서 가중치의 조정을 위해서는 곧 현재 출력값과 실제 정답값이 "얼마나 비슷한지(가까운지) 에 대한 측정" 이 필요하다.
이러한 측정 방법으로는, 크게 거리 기반 측정 방법, 확률 기반 측정 방법이 있다. 이를 보통 비용 또는 손실로 표현하기도 한다.

가중치 업데이트: 거리 기반 측정 방법
마지막 출력 값이 실제 정답값과 거리적으로 비슷하도록 유도 된다. 여기서 거리라는 것은 벡터사이의 거리(가까운 정도)를 말하며 벡터의 크기를 측정하는 norm(노름) 기반 거리 측정 방법이 주로 쓰인다.
크게 2가지 방법이 있으며 L2 norm 기반인 유클리디안 거리 측정방법, L1 norm 기반인 맨하튼 거리 측정방법이 있다.
유클리디안 거리 측정 방법
두 지점에 대해 직선을 그릴 때 직선의 길이의 합을 말한다.

직각 삼각형에서 빗변의 길이를 구하는 피타고라스의 정리를 생각해보면 이해가 쉽다.

멘하튼 거리 측정 방법
두 지점에 대해 직각으로 이어진 선의 길이의 합을 말하며 멘하튼 같은 사각형의 도시에서 원하는 곳으로 찾아가기 위해 빌딩 사이의 도보를 걸어가는 것이라고 이해하면 된다.

두 방법의 차이는 예를 들어 어떤 건물에서 정문과 엘레베이터 사이의 거리를 계산해본다고 하였을 때 각 방법은 다음과 같다.

가중치 업데이트: 확률 기반 측정 방법
마지막 출력 값이 실제 정답값과 확률적으로 비슷하도록 유도 된다. 확률 이기 때문에 출력 값의 모든 값은 0이상 1이하여야 하며 합이 1이여야 한다.
출력 값을 확률 분포처럼 만들기 위해 시그모이드라는 함수가 등장한다.
시그모이드는 S자형 곡선을 갖는 함수로써 모든 실수 입력값을 0보다 크고 1보다 작은 수로 변환하는 특징을 갖는다.
특히 이 시그모이드함수는 정규분포의 누적 확률 분포와 모양이 비슷하여 모든 값을 정규분포에 근사하고 미분 가능한 확률 분포로 변환 해준다.

참고로 시그모이드는 보통 두개중 하나를 선택하는 이진분류에서 주로 쓰이며 여러 개 중 하나를 선택하는 다중 분류의 경우 소프트맥스라는 함수를 사용하게 된다.


여기서 손실 함수에선 크로스-엔트로피라는 개념이 등장하며 엔트로피는 여러 물질이 무질서하고 무작위한 상태에 분자간 충돌로 높은 에너지가 발생하는 것을 뜻한다.

낮은 엔트로피이면 서로 잘 정리가 되어 있고 분류하기가 쉬워진다. 반대로 높은 엔트로피의 경우 서로 혼합되어 구별하기가 어렵다. 손실 함수의 크로스-엔트로피의 목적은 곧 이러한 엔트로피를 낮추는 것이다.
크로스-엔트로피는 시그모이드 또는 소프트맥스 를 통과시킨 확률 값과 실제 정답 값을 곱하고 더한 값을 구한다.

y_hat 배열에서 각각 1번이 코끼리일 확률 50%, 2번이 물고기일 확률 80%, 3번이 토끼일 확률이 40%일 때 크로스-엔트로피의 값은 약 0.6이며 각 확률이 100% 일때 0이 된다. 즉 모델은 이 크로스엔트로피의 값을 0과 가까운 값으로 계속 조정하면 되는것이다.
가중치 업데이트: 역전파
이제 이러한 손실 값으로 각 레이어가 갖고 있는 가중치를 업데이트할때 손실 값은 모델의 종단(최종 출력)에서 계산되고 반대 방향으로 레이어의 가중치를 업데이트 한다. 이렇게 순서가 역행 하기 때문에 역전파(Backpropagation) 라는 이름으로 불린다.
가중치 업데이트: 경사하강법
가중치를 업데이트하는 가장 단순한 방법으로 경사 하강법이 있다.

예컨대 당신이 어떤 이름모를 산위에 위치해 있고 이제 산 아래로 내려가기를 원할때, 가장 단순한 방법으로 현재 내 위치보다 낮은 곳으로 향하는것이다. 내 위치보다 낮은 위치로 계속 이동하다 지면과 가까워지면 그만큼 경사가 낮아지며 이는 곧 우리가 지면에 도달 할 수 있음을 뜻한다.
이를 모델에 적용하면 경사(기울기)는 곧 미분임으로 t시점의 미분을 통해 기울기를 구하고 각 가중치에 적용을 N번 반복 함으로써 학습이 이루어진다.
마지막 손실 값으로 전체 모델의 가중치를 업데이트 하기 위해 손실값을 모델의 전체 가중치로 미분했을 때
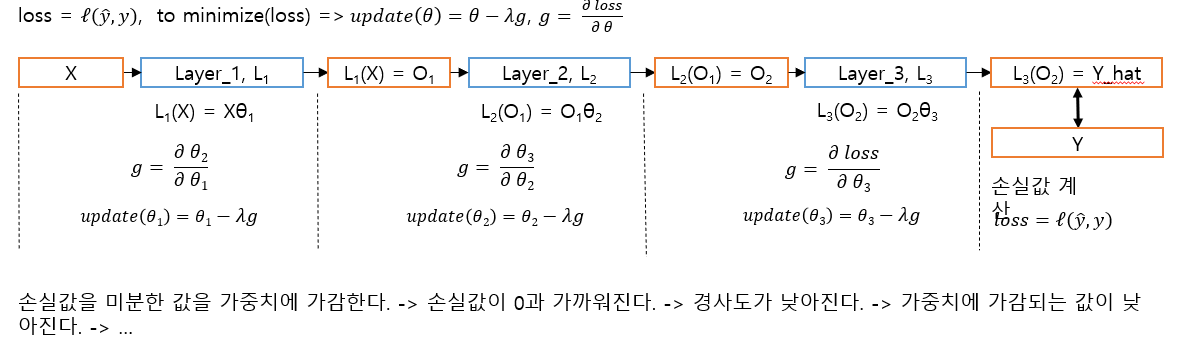
이와 같은 역방향으로 흘러가며 어느 순간 손실 값을 0과 가깝게 조정이 된다면, 이 모델은 훌륭하게 우리가 원하는 목적에 도달 한다고 볼 수 있다.
정리
모델의 크기는 곧 가중치 크기의 총합+a을 의미하며 가중치의 크기는 패턴이나 특징을 표현하고 학습하는 능력을 의미한다.
출력 값은 (지도 학습 인 경우) 원하는 값과 가까운 값으로 유도 되며 이를 통해 관측되지 않은 값으로 부터 예측(추론, 할당)을 한다.
손실 값은 비용 값이라고도 하며 실제 원하는 값과 모델의 출력 값의 차이를 추정하는 값이다.
가중치 업데이트는 손실 값을 낮추는 방향으로 업데이트 하게 되고 업데이트 순서가 마지막 레이어부터 처음 레이어로 반대 순서로 가기 때문에 역전파라고 불린다.
경사하강법은 가중치를 업데이트 할 때 손실 값을 각 레이어의 가중치에 대해 미분을 하였을 때 낮은 값(즉 변화량이 적음)이 되도록 미분 값을 가중치에 감소 시키는 최적화 모형이며 현재에도 자주 사용되는 여러 최적화 모형의 베이스 모형이다.

'AI 이야기' 카테고리의 다른 글
| Multi Modal Model (1) | 2026.04.21 |
|---|---|
| Text Generation Model (1) | 2026.04.18 |
| Convolutional Neural Network 기초 (1) | 2026.04.18 |
| 인공지능에 대한 이해 - 2 (1) | 2026.04.17 |